
"Digit Tutor" — a simple online game for kids in Svelte, which uses speech recognition engine to train pronounciation of digits: from "0" to "9".
The project is open-source, so, feel free to send a PR, if you wish!
This post contains three parts:
It all started when my son began to show interest to actually understand what those strange "0", "1", etc. mean. Some time ago, I've heard, that kids like talking to Alexa (and other voice assistants), and that it also helps with improving their speech:
So the idea was simple: have an app to show some digit, like "7", on a screen and wait for correctly pronounced "seven", than show some other random digit.
Both items from the list above joined very well, as I have remembered, that there is SpeechAPI in today's browsers (partially supported).
So, building a game, available to almost everyone, was just a matter of me going through that API.
To add some more challenge, I have selected a much-loved and still-fresh frontend library Svelte. All the initial development was done in Codesandbox, so that I even did not have to install anything locally.
Before we jump to hardcore details about building speech recognizing games, let me give an overview of what Svelte is, and how it is different from Angular, React and Vue.
Svelte is the most popular one from the "disappearing frameworks" group. Technically, this isn't even a library, as it does not have any footprint in your app — instead, it is a compiler, which goes through your code and creates an app and all the functions, that are needed for your app, but nothing more. So, if you app is just a static site — there will not be any javascript "compiled" by Svelte. On the contrary, React/Angular/Vue core libs are always required in your app.
As Svelte has "compilation" step as part of building and app, at which it already knows about all the possible changes to your DOM structure, it does not have (and does not need to have) virtual DOM. If you just need to change the value of an input — Svelte will see that and create just the code to change input's value; nothing more and no VDOM involved. Svelte developers blog calls VDOM a "pure overhead".
Besides, working with Svelte, I have experienced some cool features, some of which are even missing from React, while some might be considered a disadvantage:
let i = 0;
while (i < 3) {
i++;
}
console.log(i);
<script>
let count = 0;
function handleClick() {
count += 1;
}
</script>
<style>
/* Svelte makes sure, this css is scoped to just your component */
button {
background: #ff3e00;
color: white;
border: none;
padding: 8px 12px;
border-radius: 2px;
}
</style>
<button on:click="{handleClick}">
Clicked {count} {count === 1 ? 'time' : 'times'}
</button>
There is no need for hooks or setState — just like in Vue, Svelte makes
use of js class getters/setters. Downside of this, is that you have to use
immutable structures, or give Svelte hints: arr.push(x) will not be noticed
as a change, arr = [...arr, x] is a canonical way to push to arrays in
Svelte.
You cannot use js in your templates (like you can in JSX): any specific
logic should be expressed via Svelte-specific constructions, like
{#if X == Y}<conditinally rendered HTML>{/if}. This is not inconvenient,
but pure js is something everyone already knows, so could be a point to
improve.
State. What an important word to know for React/Vue/Angular developers! Surprisingly, Svelte has something to offer in state management out-of-the-box, which is called "Stores". On the high-level, anything you can subscribe to and write/read from can be a store in Svelte (sometimes just 2-function-object is enough). I have not yet seen issues in working with shared state between different components, yet, as I have seen in React.
After a short warm-up with Svelte, I found it very convenient and quite easy to get up and running with it. Codesandbox.io supports it quite well, so there is no need to set up everything locally. However, if you prefer using local VSCode, I would suggest going on with VSCode Remote Development plugin, so that you don's intall node and all modules locally. This plugin even lets setting up some VSCode extensions, like Prettier, remotely.
As for the Svelte features, everything seemed convenient and well-thought. I had
couple issues with Svelte not seeing array updates (see item#2 above) and being
unable to style a Svelte component from root-component (the fix is to wrap
component to a div or make sure it captures additional style from props).
Otherwise, tutorial at svelte.dev was quite
comprehensive and covered everything required.
Would I recommend using Svelte in production? Yes, if you're working with a web-site (not web-app), which is not very dynamic and delivers, mostly, static content. Although there are good react-based static site generators, Svelte will always win in initial bundle size, while being equal in performance. It is also quite mature now, as current major version is 3, meaning three major releases are done now.
Speech recognition in the app is based on SpeechAPI. It is not really supported in many browsers, as of now: https://caniuse.com/speech-recognition. Here is a screenshot of that page at the time of writing this text:
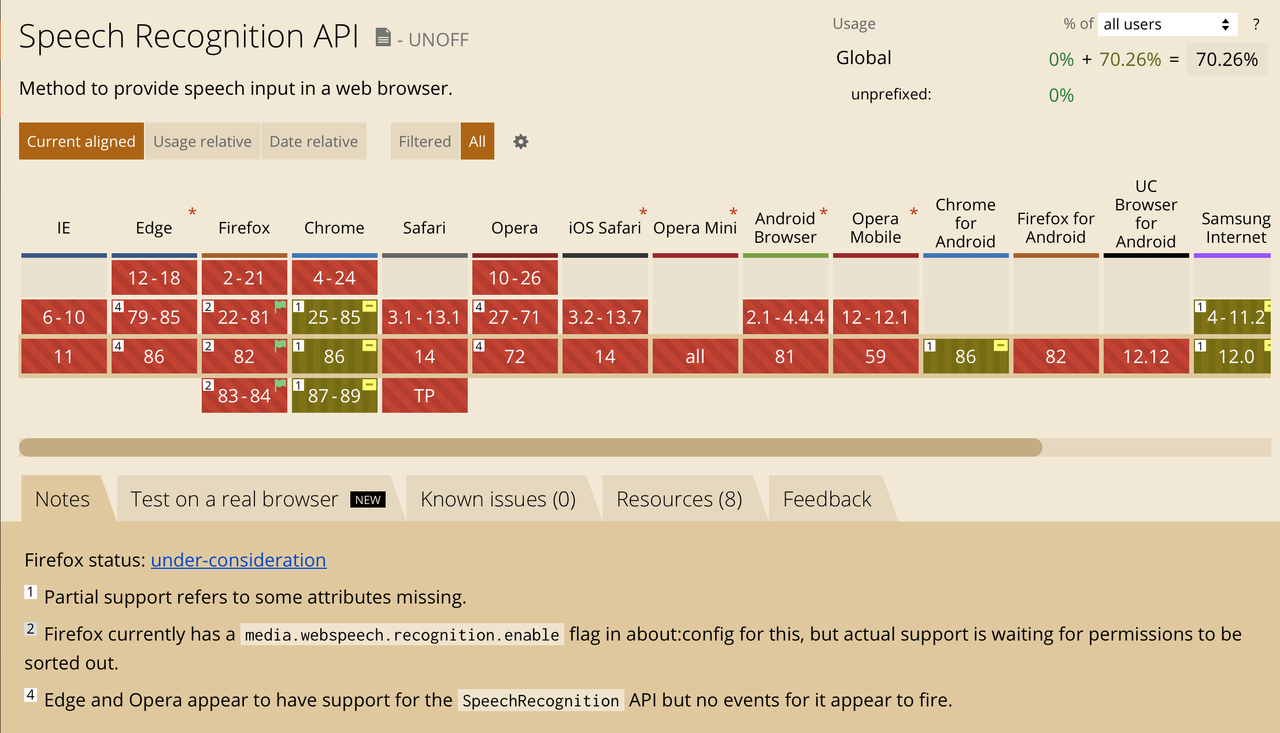
As you see, the support matrix can be quickly described as "chrome-only",
however, Firefox can also support it with some config. Other browsers either
don't support it at all, or have required objects in window, which do nothing.
So, it is definitely not ready for cross-browser production usage, but fits for experiments, like our game.
As you might guess, speech recognition in browsers contains of three parts:
Logically, there might also be something like "intent recognition", to understand what the user really means, but it seems that current technology state does not allow to do that reliably.
At first, and very logically, I thought I would need to support Grammar and Recognition in my game. Later, during the testing stages, I've figured out, that grammar part is not used at all, so I could only focus on recognition.
It turned out, that Chrome has very peculiar speech recognition implementation:
Note: On some browsers, like Chrome, using Speech Recognition on a web page involves a server-based recognition engine. Your audio is sent to a web service for recognition processing, so it won't work offline.
Keep a note on these details, in case you care about privacy and Grammar support.
The first thing to do is to get & check if Speech objects are in the window. I
am using a very simple approach here, with only one idea of having it all as a
separate module. Actual
file is here:
import { locale } from "./locale.js";
const SpeechRecognition =
window.SpeechRecognition || window.webkitSpeechRecognition,
SpeechGrammarList =
window.SpeechGrammarList || window.webkitSpeechGrammarList,
// SpeechRecognitionEvent =
// window.SpeechRecognitionEvent || window.webkitSpeechRecognitionEvent,
grammar =
"#JSGF V1.0; grammar colors; public <color> = " +
locale.getCurrentLocale().numbers.join(" | ") +
" ;";
let recognition, speechRecognitionList;
if (SpeechRecognition && SpeechGrammarList) {
recognition = new SpeechRecognition();
speechRecognitionList = new SpeechGrammarList();
speechRecognitionList.addFromString(grammar, 1);
recognition.grammars = speechRecognitionList;
recognition.continuous = true;
recognition.lang = locale.getCurrentLocaleCode();
recognition.interimResults = true;
recognition.maxAlternatives = 1;
}
export default recognition;
Here we are initializing everything we need (even grammar):
window.SpeechRecognition || window.webkitSpeechRecognitionnewNote, that for grammar initialization I am using a separate module called "locale", since grammar depends on current language. Later, I understood, that grammar isn't actually used.
Before jumping to configuration details, I'll describe how to use that
recognition instance:
.start() — this is the place, when browser asks for mic access and
actual listening to user's speech starts.onresult events. Each event may be "final" or "interim".
"Interim" result is something you get quite randomly and often, while the
user is still speaking. "Final" result is sent as soon as user has stopped
speaking and is silent for some cooldown period..stop() or .abort(), if/when needed. My implementation calls "abort"
after a successfull digit guess, and calls start quickly after that. The
difference between them is, that "stop" attempts to return one last "final"
result, while "abort" does not.The configuration details:
.grammars: list of grammars, that you would want to recognize. Not really
used, but might be in future, so I still have it.continuous: true if you want to receive multiple final results, or
false in case you need just one final result. Since my game is more or
less continuous, I have it as true.lang: recognition language. I am getting it from current system settings,
so everyone gets his/her native languageinterimResults: when true, you will get "interim" onresult events. Those
happen faster, but may contain partially or incorrectly recognized words. I am
using this, to improve recognition percieved performance: even if the interim
result contains correct digit, it is considered pronounced correctly. This
makes game much more responsive.maxAlternatives: how many recognition options do you need. These are
usually similarly sounding words and their combinations. Using "1" in my code,
as I only need one optionNow, as we have properly initialized all required objects, we need to:
The instance usage is simple: call .start() to start listening, and subscribe
to .onresult event to handle results.
There are also things like .onerror and .onnomatch events: I am using them
just to show those errors to user, haven't seen them actually fire, yet.
Let's dive into .onresult
implementation;
below is its annotated version:
recognition.onresult = function (event) {
console.log(event); // who doesn't like a good console.log?
// Extract "current" result from all existing
// results; this event also stores older results,
// till the "final" result is in.
const result = event.results[event.resultIndex];
const transcript = result[0].transcript.toLowerCase();
// this is for Svelte, to show hint on screen:
// "what was heard by computer"
hint = transcript;
// Some more logging
console.log("Result received: " + transcript + ".");
console.log("Confidence: " + result.confidence);
// Here we check, if expected digit was pronounced
// Sometimes Chrome recognizes them as words (e.g. six),
// sometimes as digits (e.g. 6). Computers aren't clever
// enough to handle those cases, so we need an IF with OR
if (
transcript.indexOf(digit) >= 0 ||
transcript.indexOf($l.numbers[digit]) >= 0
) {
// Handle correct digit: show big green chek and next one
onCorrectDigit();
} else {
// I had specific handling for incorrect pronounciation
// But those event fire quite often, so I decieded to
// not do anything in case answer is not correct.
// onFail();
}
};
Can you spot a bug in the code above? If you need to say "six", and you say "twenty six", this will still count as correct. Not a big deal, I think.
As you see, this code works with Svelte and UI, but it isn't impacted in almost
any way by Svelte. The cool thing is in this line
transcript.indexOf($l.numbers[digit]) >= 0. $l here is a Svelte store, and
it will always refer to the current locale, so it will look for correct words as
digits.
The last piece of code related to recognition is in onCorrectDigit handler. It
calls .abort() and .start() once again, to clear the results array and make
sure the app memory footprint is consistently low. I think, it would work even
without that restarting, but this feels correct.
That's all! We've covered 100% of lines, related to speech recognition in the app. As you see, there's nothing complex and hard work is abstracted away by the browser. The only piece not covered is handling missing SpeechAPI; this is fairly straightforward, so omitted here.
If I was implementing it, probably, I would go with a simpler arguments for
.onresult event, but it takes just 2 more minutes, to figure out its structure
and, probably, covers more cases, than mine.
Also note once again, that this all is almost Chrome-only for now, so cannot consider it "production-ready".
In the third Digit-Tutor article I will cover localization implementation: Svelte has a built-in approach, however, I've opted for a custom, store- based implementation, since I had to integrate that with speech recognition, too. What I got, I called a "poor man's localization for Svelte" as it felt simpler and more flexible than the built in one in the end.
At first, we need to understand what Svelte Stores are and how they work:
A store is simply an object with a
subscribemethod that allows interested parties to be notified whenever the store value changes.
Here is a simple, but feature-complete store example:
import { writable } from "svelte/store";
function createCount() {
// this line creates a "writable" store, with "0" initial value
// and gives subscribe, set and update methods
// this really resembles "useState" from react
const { subscribe, set, update } = writable(0);
return {
subscribe,
increment: () => update((n) => n + 1),
decrement: () => update((n) => n - 1),
reset: () => set(0),
};
}
As you can see, store does not necessarily exposes direct "set" or "update" methods — if you want to limit its updates to some specific cases (increment/decrement/reset in the sample) — this is all achievable.
There is also one more Svelte-magic with stores: you don't actually need to use
subscribe method or anything, to use store value in code or UI, just use the
magic $ sign. Here is how we could use our sample store in the code:
<script>
import { count } from './stores.js';
</script>
// this is where the magic happens, and `count` from the store
// is reactively bound to the UI
<h1>The count is {$count}</h1>
<button on:click={count.increment}>+</button>
<button on:click={count.decrement}>-</button>
<button on:click={count.reset}>reset</button>
So, stores seem to be fully sufficient to implement internaionalization:
$store.valueMy internationalization implemenetations lives in the
locale.js
file, and provides following features:
It is implemented as a writable store, whose value is an object, storing localized versions of all the strings in the app. That object is loaded from the data-file.
The store itself is used just like a usual Svelte store, which is referred as a
$l in the code. Whenever selected locale changes, the underlying store object
is replaced with a new one, and all UI elements change their values:
// fragment of the App.js file
<h1>{$l.header}</h1>
{#if gameState == STARTING || gameState == NO_RECOGNITION}
<LocaleSelector />
{/if}
<p>{$l.info}</p>
Unfortunately, there was exactly one bug in the "release" version of the game, and it was connected to internationalization. Besides it, I have covered all possible corner casees with the locales, so let's just discuss the bug.
The reason for it was, that in the LocaleSelector component, I haven't
initialized the selectedLocaleCode value the user's OS locale. As a result,
its initial value was undefined, while the UI was showing English locale as
selected — just the first one in the list; at the same time, all the logic,
including speech recognition, was using real user's locale (russian, in my
case).
The fix is pretty simple: I just made sure, that this variable is properly initalized in the component, too. Here is the fix, which I have done 20 minutes since the bug was reported.
It turned out, that Svelte stores is a sufficiently powerful concept to implement the internationalization. I cannot imagine anything similar from React-world, except third-party libs.
And it also turned out, that you need to be twice as thorough and attentive, when making an internationalized app, since it can be a source of additional bugs.
Anyway, I hope people liked this game, since that time I have even received multiple improvement and evolution ideas, which may some day go to production, we'll see!
Thank you!